Everyone knows that local minima and maxima of a function 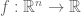 are critical points, i.e. points where the gradient is equal to zero. This is what we call an optimality condition, a condition verified by every solution of a minimization or maximization problem.
are critical points, i.e. points where the gradient is equal to zero. This is what we call an optimality condition, a condition verified by every solution of a minimization or maximization problem.
The situation changes when dealing with constraints. Consider a simple example, like  and note that the gradient of the objective function is not zero at the optimal solution
and note that the gradient of the objective function is not zero at the optimal solution 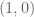 . The idea is that one needs to take into account the constraint when writing optimality conditions in this case. This leads us to consider the theory of Lagrange multipliers. Every student finds this concept a bit difficult when seen for the first time.
. The idea is that one needs to take into account the constraint when writing optimality conditions in this case. This leads us to consider the theory of Lagrange multipliers. Every student finds this concept a bit difficult when seen for the first time.
Since a picture is worth 1000 words, let me share with you two pictures 🙂 Consider the minimization of  under the constraint
under the constraint  . The first photo below shows the gradients of the function and the constraint at the optimal solution approximated numerically. One striking property becomes obvious: the gradient of the function aligns with the gradient of the constraint. In order to see why this is necessary, let us look at another point in the constraint set where the two gradients
. The first photo below shows the gradients of the function and the constraint at the optimal solution approximated numerically. One striking property becomes obvious: the gradient of the function aligns with the gradient of the constraint. In order to see why this is necessary, let us look at another point in the constraint set where the two gradients 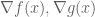 are not aligned, shown in the second picture.
are not aligned, shown in the second picture.
It becomes obvious that if the two gradients are not aligned, then there exists a component of 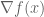 which is tangent to the constraint set. Therefore, going along this direction, in its opposite sense it is possible to further decrease the value of the function
which is tangent to the constraint set. Therefore, going along this direction, in its opposite sense it is possible to further decrease the value of the function 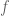 , while still following the constraint set. Therefore, when the two gradients are not aligned we are not at a minimum (the same type of argument works for maximizing problems).
, while still following the constraint set. Therefore, when the two gradients are not aligned we are not at a minimum (the same type of argument works for maximizing problems).
Of course, this geometric argument is not the whole picture, but it gives an important insight, which directly implies the theory of Lagrange multipliers: at the optimum, the gradient  should be orthogonal to the tangent space to the constraint set, and this orthogonal, under some regularity assumptions, is generated by the gradients of the constraints themselves, giving the famous relation
should be orthogonal to the tangent space to the constraint set, and this orthogonal, under some regularity assumptions, is generated by the gradients of the constraints themselves, giving the famous relation

Now, once we understood the intuition behind this, it remains to see under which conditions there exists a tangent space to the constraints set, and see rigorously why the above relation holds. But all this is left for some future post.




