Shape Optimization Course – Day 4
Here I will present the contents of the fourth day of the Shape Optimization Course held in Timisoara, Romania in November 2011. The last two lessons were about the numerical computations used in shape optimization. Since I am not a very good numeric analyst, I may have not understood well all that was said in these courses… Therefore, if you find some mistakes they are not due to the speaker, but due to my misunderstanding.
Speaker: Edouard Oudet
When we are talking about shape optimization, we want to find a shape which satisfies an optimality condition. Usually this condition is written as a minimum or maximum problem. For this, we need a functional

which attaches to every subset 


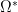

where 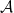



The first aspect we are concerned of is the existence of the solution to this problem. After proving that the solution exists, we may ask ourselves which is this solution? Is it a ball, is it not a ball, is it a regular shape? Since sometimes the class of admissible shapes is very large (measurable sets, disconnected sets), our solution may be irregular, and our intuition may not show us neither the right optimal shape nor the properties of this shape (symmetry, conectedness, etc). This is where numerical analysis comes into play.
In standard numerical optimization we are concerned with functions 

One method to solve this kind of problems is the gradient method, which is to start from a chosen 
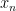
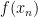

where 

What is the difference between numerical optimization and numerical shape optimization? Well, first difficulty is defining the gradient of the shape function 
As an example, let’s look at the problem of minimizing 


It is well known that for every

such that 
It would be interesting to know what are the optimal shapes for 
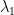


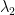
Surprisingly, for 
For this you can check out the work of Edouard Oudet and more recently Pedro Antunes and Pedro Freitas who give candidates obtained by numerical analysis for the first few eigenvalues.
Let’s pass now to another problem which is about partitioning the space with optimal sets in the sense that each set of the partition has fixed measure, and we want to minimize the sum of the perimeters (asymptotically, of course).
In the plane the problem was known as the Honeycomb Conjecture, which says that in the plane the optimal partition into sets of equal area which minimizes the total perimeter is asymptotically a partition in hexagons, which resembles the shape of a honeycomb. This conjecture was inspired, as the title says, by the fact that if the bees, which are very efficient workers, choose that pattern it should be very close to an optimal pattern, because it saves both time and material to build. In nature, often optimum tends to be achieved…
This is not a conjecture any more since in 2001 it was proven by Hales. However in the 3 dimensional case things are not so simple, since we cannot partition the space into pieces having the same form. Kelvin’s conjecture proposed such a tilling which was then improved by Weaire and Phelan. You can also see the work of Edouard Oudet on this subject here. The main tool used is a variant of Modica Mortola theorem.
How does a numerical algorithm for finding the optimal shape for
- Start from a shape
.
- Compute
and its corresponding eigenvector
.
- Compute the gradient of
.
- Define a perturbation
of the boundary
- The new set is
.
This is called the boundary variation method. One of the problems with this method is that it preserves the topology of the domain (connectedness, number of connected components), and therefore the starting point must be good in order to reach a good result.
For larger eigenvalues, numerical approximation becomes more tricky. It is known that the eigenvalue is differentiable if and only if the eigenvalue is simple. Surprisingly, numerical tests suggest that every optimizer for 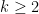
A problem similar to the honey comb problem is the problem of optimal partitions which minimize the sum of corresponding eigenvalues. For example

where 


This problem was studied by D. Bucur, E. Oudet and B. Bourdin. Existence results and numerical computations can be found here. It is conjectured that asymptotically the solution behaves as in the honey comb conjecture, i.e. assymptotically the optimal partition for the first eigenvalue is the one in regular hexagons.
Beni Bogoşel

Click to see my CV
Today’s Visitors

Click for more info
