Archive
Iterative algorithms – Convergence rates
In optimization and any other iterative numerical algorithms, we are interested in having convergence estimates for all algorithms. We are not only interested in showing that the error goes to 
Generally, there are two points of view for convergence: convergence in terms of 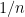


To fix the ideas, denote 
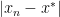
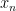

We have the following standard classification:
- linear convergence: there exists
such that
the constant
, so in particular
.
- sublinear convergence:
- superlinear convergence:
with any positive convergence ratio
- {convergence of order
}: there exists
such that for
large enough
is called the order of convergence
has a special name: quadratic convergence

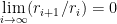
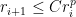
To underline the significant difference between linear and superlinear convergence consider the following examples: Let 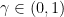
converges linearly to zero, but not superlinearly
converges superlinearly to zero, but not quadratically
converges to zero quadratically
Quadratic convergence is much faster than linear convergence.
Among optimization algorithm, the simpler ones are usually linearly convergent (bracketing algorithms: trisection, Golden search, Bisection algorithm, gradient descent). Algorithms involving higher order information or approximation are generally superlinear (Secant method, Newton, BFGS or LBFGS in higher dimensions etc.).
There is a huge difference between linear convergence and super-linear convergence. If a faster algorithm is available using it is surely useful!
Golden search algorithm – efficient 1D gradient free optimization
Bracketing algorithms for minimizing one dimensional unimodal functions have the form:
- Suppose
is an interval containing the minimizer
- Pick
in
- If
then choose
- If
then choose
- Stop the process when
![{[a_{n+1},b_{n+1}] = [a_n,x^+]}](https://s0.wp.com/latex.php?latex=%7B%5Ba_%7Bn%2B1%7D%2Cb_%7Bn%2B1%7D%5D+%3D+%5Ba_n%2Cx%5E%2B%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[a_{n+1},b_{n+1}] = [x^-,b_n]}](https://s0.wp.com/latex.php?latex=%7B%5Ba_%7Bn%2B1%7D%2Cb_%7Bn%2B1%7D%5D+%3D+%5Bx%5E-%2Cb_n%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
The simplest algorithm corresponds to choosing 

Optimizing a 1D function – trisection algorithm
Optimization problems take the classical form
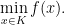
Not all such problems have explicit solution, therefore numerical algorithms may help approximate potential solutions.
Numerical algorithms generally produce a sequence which approximates the minimizer. Information regarding function values and its derivatives are used to generate such an approximation.
The easiest context is one dimensional optimization. The basic intuition regarding optimization algorithms starts by understanding the 1D case. Not all problems are easy to handle for a numerical optimization algorithm. Take a look at the picture below:

Find coefficients of trigonometric polynomial given samples
Suppose the values 

are known for a set of distinct angles ![{\theta_i \in [0,2\pi]}](https://s0.wp.com/latex.php?latex=%7B%5Ctheta_i+%5Cin+%5B0%2C2%5Cpi%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

Question: Recover the coefficients of the trigonometric polynomial 
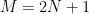
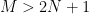
Answer: Obviously, since there are 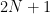


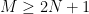

This function is a sum of squares, which has zero as a lower bound. The function 


A straightforward computation shows that the gradient of
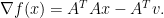
The 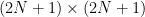





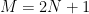
Below, you can find a Python code which solves the problem in some particular case.
import numpy as np
import matplotlib.pyplot as plt
N = 5 # coeffs
M = 2*N+1 # M>=2N+1 samples
# function to be approximated
def fun(x):
return np.sin(x+np.sqrt(2))+0.3*np.sin(5*x-np.sqrt(3))+0.1*np.sin(8*x-np.sqrt(7))
thetas =np.linspace(0,2*np.pi,M,endpoint=0)
dthetas =np.linspace(0,2*np.pi,1000,endpoint=1)
# values of the function at sample points
vals = fun(thetas)
A = np.zeros((M,2*N+1))
# construct the matrix of the system
A[:,0] = 1
for i in range(0,N):
A[:,i+1] = np.cos((i+1)*thetas)
A[:,N+i+1] = np.sin((i+1)*thetas)
coeffs = np.zeros(2*N+1)
B = (A.T)@A
print(np.shape(B))
# solve the system to find the coefficients
coeffs = np.linalg.solve(B,A.T@vals)
# function computing a trigonometric polynomial
def ptrig(x,c):
res = np.zeros(np.shape(x))
res = c[0]
n = len(c)
m = (n-1)//2
for i in range(0,m):
res = res+c[i+1]*np.cos((i+1)*x)+c[i+m+1]*np.sin((i+1)*x)
return res
vals2 = ptrig(thetas,coeffs)
# plotting the result
plt.figure()
plt.plot(thetas,vals,'.b',label="Sample values")
plt.plot(dthetas,fun(dthetas),'g',label="Original function")
plt.plot(dthetas,ptrig(dthetas,coeffs),'r',label="Fitted trigonometric polynomial")
plt.legend()
plt.savefig("TrigPoly.png",dpi=100,bbox_inches='tight')
plt.show()For the parameters chosen above the program outputs the following result. You can play with the input parameters to observe the changes.

Construct Pythagorean triangles with given constraints
This post will present some ideas related to the generation of all Pythagorean triangles satisfying a certain criterion, from an algorithmic point of view. Of course, there are infinitely many such triangles (integer sided with a right angle). Denoting by 



When 

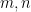

These formulas are attributed to Euclid. The case 
1. Generate all pythagorean triangles with edges 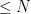
2. Generate all pythagorean triangles with 

3. Generate all pythagorean triangles with 
Now let’s answer these questions one at a time:
1. In order to generate pythagorean triangles with edges 

- set an empty list
- loop for
to
- loop for
to
,
,
- loop for
and add the triangle
to the list
- loop for
- in the end
will contain the desired triangles

2. In this question one of the two legs 
: for all divisors
with
: find all factorizations
and check again that
3. In this case 

where
These tools might come in handy when working on Project Euler problems, since often when dealing with integer sided quantities in a triangle, things can be reduced to pythagorean triangles. When you reach this step, it is enough to loop on these triangles and perform the requested operations.
Sum of floors of multiples of the Golden Ratio
Propose an algorithm for computing

for 

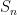
Solution: Computing a floor function and a multiplication is not complicated, therefore proposing a 

The path to a much more efficient algorithm goes through the notion of Beatty sequence. For a positive irrational number 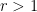




It is obvious now that 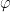



- denote by
, the largest term in
- looking at all the integers up to
or of the form
(in the associated complementary sequence).
- denote by
the largest integer such that
, which is given by
. Then, it is not difficult to see that
.
- In the end we obtain
- by convention, state that
or
.

The last item above shows that a recursive algorithm can be implemented in order to compute 

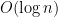
The algorithm for computing
Other values of 


Compute recurrent sequences fast
In many programming questions the computation of a recurrent sequence might be necessary. One of the famous such sequences is the Fibonacci sequence defined by 

Writing a code which computes 
First, remember that it is possible to have an exact formula:

where 

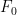
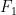


1. Recursion. The simplest way to code the computation of 


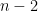

In order to see why, it is enough to note that when computing 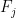



2. Iterative sequence. The second approach is more efficient. You only need two variables, 

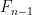
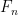




3. Matrix exponentiation. One interesing approach, which is really fast is rewriting the second order recurrence as a first order matrix recurrence:

This implies that 

Please note that you can generalize this to recurrences of the form

It suffices to see that

so in the end you just need to compute the exponential of a bigger matrix. The complexity stays the same!
What to remember from this post?
- Don’t use recursion (without memoization) when computing recurrent sequences. You won’t get very far and you’ll waste your ressources!
- You can compute the
Are zero-order optimization methods any good?
The short answer is yes, but only when the derivative of gradient of the objective function is not available. To fix the ideas we refer to:
- optimization algorithm: as an iterative process of searching for approximations of a (local/global) minimum of a certain function
- zero-order algorithm: an optimization method which only uses function evaluations in order to decide on the next point in the iterative process.

Therefore, in view of the definitions above, zero-order algorithms want to approximate minimizers of a function using only function evaluations; no further information on derivatives is available. Classical examples are bracketing algorithms and genetic algorithms. The objective here is not to go into detail in any of these algortihms, but to underline one basic limitation which must be taken into account whenever considering these methods.
In a zero-order optimization algorithm any decision regarding the choice of the next iterate can be made only by comparing the values of ![{[a,b]}](https://s0.wp.com/latex.php?latex=%7B%5Ba%2Cb%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[a,x^*]}](https://s0.wp.com/latex.php?latex=%7B%5Ba%2Cx%5E%2A%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[x^*,b]}](https://s0.wp.com/latex.php?latex=%7B%5Bx%5E%2A%2Cb%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
- given the bracketing
choose the points
and
.
- compare the values
and
in order to decide on the next bracketing interval:if
then
if
then
- stop when the difference
is small enough.
![{[a_{i+1},b_{i+1}]=[a_i,x_+]}](https://s0.wp.com/latex.php?latex=%7B%5Ba_%7Bi%2B1%7D%2Cb_%7Bi%2B1%7D%5D%3D%5Ba_i%2Cx_%2B%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[a_{i+1},b_{i+1}]=[x_-,b_i]}](https://s0.wp.com/latex.php?latex=%7B%5Ba_%7Bi%2B1%7D%2Cb_%7Bi%2B1%7D%5D%3D%5Bx_-%2Cb_i%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
One question immediately rises: can such an algorithm reach any desired precision, for example, can it reach the machine precision, i.e. the precision to which computations are done in the software used? To fix the ideas, we’ll suppose that we are in the familiar world of numbers written in double precision, where the machine precision is something like 
More precisely, the real numbers are stored as floating point numbers and only 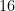

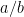


This issue related to computations done in floating point precision makes the question of comparing 



where 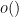
Coming back to our previous paragraph, it turns out that the computer won’t be able to tell the difference between 


where

the machine won’t tell the difference between 
Therefore, when using a zero-order algorithms for a function 
When using derivatives or gradients there is no such problem, since we can decide if we are close enough to 
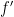
In conclusion, use zero-order methods only if gradient based methods are out of reach. Zero-order methods are not-only slowly convergent, but may also be unable to achieve the expected precision in the end.
On Heron’s algorithm – approximating the square root
Heron’s algorithm computes an approximation of the square root of a positive real number using the iteration

- Show that the recurrence defined above is Newton’s algorithm applied for finding a zero of the function
. Show that the sequence
converges to
when
is close enough to
This choice simplifies the computations and is an estimation of half the relative error when
.
- Show that the sequence
Deduce an explicit formula for
in terms of
. Show that the sequence
.
- Show that for every
there exists an integer
such that
. Write a modified Heron algorithm which reduces the computation of the square root of
.The choice of the initialization
and we look at the choice of the initial condition. We will suppose that the initial condition depends on
, a constant function and
, a polynomial of degree
. In every case we will try to minimize
for
.
- Show that if
then
is minimal for
. Find the explicit value of
. (Hint: You could represent graphically the function
.)
- Suppose that
with
.
(a) Prove that the maximum ofis found for
.
(b) Show that in order to minimizeit is necessary that
and that
.
(c) Conclude that the. Find an exact expression for
- For
compare the number of iterations necessary to arrive at a demanded precision (
for the two initializations studied:
and
with
- Evaluate the number of operations used for the two cases and conclude which of the two approaches is more advantageous.
- Try to find the initialization of second degree which is optimal and perform a similar investigation to see if from the point of view of the number of operations this choice is well adapted or not.


p-Laplace equation – Fixed point approach
The 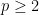

We are not going into details regarding the functional spaces corresponding to 
Project Euler tips
A few years back I started working on Project Euler problems mainly because it was fun from a mathematical point of view, but also to improve my programming skills. After solving about 120 problems I seem to have hit a wall, because the numbers involved in some of the problems were just too big for my simple brute-force algorithms.
Recently, I decided to try and see if I can do some more of these problems. I cannot say that I’ve acquired some new techniques between 2012-2016 concerning the mathematics involved in these problems. My research topics are usually quite different and my day to day programming routines are more about constructing new stuff which works fast enough than optimizing actual code. Nevertheless, I have some experience coding in Matlab, and I realized that nested loops are to be avoided. Vectorizing the code can speed up things 100 fold.
So the point of Project Euler tasks is making things go well for large numbers. Normally all problems are tested and should run within a minute on a regular machine. This brings us to choosing the right algorithms, the right simplifications and finding the complexity of the algorithms involved.
ICPC 2015 World Final Problem A
This is the solution to Problem A from the International Collegiate Programming Contest. The list of problems can be found here. This first problem consists simply of reading the parameters of the function defined below, and computing its values on the set 
The inputs are parameters 

and the values to be considered are 


function res = Prob1_2015(p,a,b,c,d,n) dis = 1:n; vals = p*(sin(a*dis+b)+cos(c*dis+d)+2); mat = zeros(n,1); for i = 1:n mat(i) = vals(i)-min(vals(i:end)); end res = max(mat)
The sample outputs are:
>> Prob1_2015(42,1,23,4,8,10)
104.855110477394
>> Prob1_2015(100,7,615,998,801,3)
0
>> Prob1_2015(100,432,406,867,60,1000)
399.303812592112
New version which works for large 

function res = Prob1_2015(p,a,b,c,d,n) dis = 1:n; vals = p*(sin(a*dis+b)+cos(c*dis+d)+2); mat = zeros(n,1); lastmax = vals(1); for i = 1:n lastmax = max(lastmax,vals(i)); mat(i) = lastmax-vals(i); end res = max(mat)
Identifying edges and boundary points – 2D Mesh – Matlab
A triangulation algorithm often gives as output a list of points, and a list of triangle. Each triangle is represented by the indexes of the points which form it. Sometimes we need extra information on the structure of the triangulation, like the list of edges, or the list of boundary points. I will present below two fast algorithms for doing this.
Finding the list of edges is not hard. The idea is to go through each triangle, and extract all edges. The algorithm proposed below creates the adjacency matrix in the following way: for each triangle ![{[i,j,k]}](https://s0.wp.com/latex.php?latex=%7B%5Bi%2Cj%2Ck%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

In order to find the points on the boundary (in two dimensions), it is enough to look for the edges which are sides to only one triangle. We can do this using the adjacency matrix. Note that if 








Below are two short Matlab codes doing these two algorithms. I guess they are close to being optimal, since only sparse and vectorized operations are used.
%p is the list of points %T is the list of triangles, ap is the number of points %this computes the adjacency matrix A = min(sparse(T(:,1),T(:,2),1,ap,ap)+sparse(T(:,2),T(:,3),1,ap,ap)+sparse(T(:,3),T(:,1),1,ap,ap),1); A = min(A+A',1); % this finds the boundary points, whose indexes are stored in Ibord B = A^2.*A==1; Ibord = find(sum(B,2)>0);
Distance from a point to an ellipsoid
Here I will discuss the problem of finding the point which realizes the minimal distance from a given
This problem is interesting in itself, but has some other applications. Sometimes in optimization problems we need to impose a quadratic constraint, so after a gradient descent we always project the result on the constraint which is an ellipsoid.
Let’s begin with the problem, which can be formulated in a general way like this: we are given 


(note that the square is not important here, but simplifies the computations later)
Beni Bogoşel

Click to see my CV
Today’s Visitors

Click for more info
