Archive
Explicit Euler Method – practical aspects
In a previous post I presented the classical Euler methods and how they apply to the simple pendulum equation. Let me now be a little more explicit regarding the coding part. I will present a Python code and give you some main ideas, important from my point of view, regarding the implementation. Here is a summary of these ideas
- Use numpy in Python. When performing numerical simulations related to ODEs it is recommended to work in floating point precision. This will give you accurate enough results (at least for usual academical examples) and will produce a more efficient code.
- Structure the code using functions. The code for the Explicit Euler method should be easily adaptable to other problems, by changing the function defining the ODE (like shown in this post)
- Any numerically implemented method for solving ODEs should be tested on a simple example where the analytical solution is known. In particular, the convergence order of the method can be identified and should coincide with the theoretical prediction. This can easily help debug implementation errors for more complex methods.
- When the ODE comes from an isolated system where there is an invariant (like the energy for the pendulum), the numerical preservation of this invariant should be tested. Errors might be seen, but they should be quantifiable in terms of the step size and the order of the method. Aberrant results here could indicate the presence of a bug.
Gradient algorithm: Quadratic Case: theory
Everyone who did a little bit of numerical optimization knows the principle gradient descent algorithm. This is the simplest gradient based algorithm: given the current iterate, advance in the opposite direction of the gradient with a given step

It is straightforward to see that if 


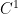

This means that there exists a 

Recurrences converging to the wrong limit in finite precision
Consider the following recurrence:

a) Study this recurrence theoretically: prove that the sequence converges and find its limit.
b) Implement the recurrence using the programming language of your choice and see what is the limit obtained by numerical investigation. Interpret the results!
Read more…Gradient Descent converging to a Saddle Point
Gradient descent (GD) algorithms search numerically for minimizers of functions 


where 
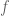
However, the “almost always” part from the above sentence is in itself interesting. It turns out that the choice of the initialization may lead the algorithm to get stuck in a Saddle Point, i.e. a critical point where the Hessian matrix has both positive and negative eigenvalues. The way to imagine such examples is to note that at such a Saddle Point there are directions for which
To better illustrate this phenomenon, let’s look at a two dimensional example:

It can be seen immediately that this function has critical points at 


Note that looking only along the line 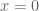




One simple way to prevent GD algorithms being stuck in a saddle point is to consider randomized initializations so that you avoid any bias you might have regarding the objective function.
What can go wrong with numerics
I recently watched the video Validated Numerics by Warwick Tucker. This video is an introduction to interval arithmetic, which is a rigorous way of doing numerics with nice applications. In the first part of the video, however, he starts by showing some examples where the numerics can go wrong.
First, in order to understand why computations done by a machine can be wrong, you need to know how the computer looks at numbers. Since the computer has a finite amount of memory, it will never store exact representations. Irrational numbers with infinitely many digits repeating without any pattern whatsoever are clearly not representable. Even rational numbers, which are the ratios of two integers may be costly to represent if the integers involved are quite large. When working with simulations one often manipulates not one variable but vectors and matrices with millions of variables. Therefore it is necessary to bound the memory allocated to each one of these variables. This is why the floating point arithmetic was introduced.
A floating point number (in some basis, binary for the computer, decimal for the usual representation) is composed of a real number m called the mantissa and an exponent e. The catch is that the mantissa will store only finitely many digits and usually it is normalized, i.e. there are no zeros after the decimal point. For example:
- 1.01011 is a valid mantissa with 5 binary digits (the leading 1 is not counted)
- 0.00101 is not a normalized mantissa since there are zeros after the decimal point
- 1011.01 is not a normalized mantissa since there are more then one digits before the decimal point
The mantissa alone, in binary representation, will only represent numbers between 1 and 2. However, one can reach more numbers using a multiplication with a power of two, contained in the exponent. Therefore, the computer knows a number by its finite precision mantissa and its exponent. The sign of the number can also be included in one bit. I will not try to make an exhaustive lecture on floating point representations: you should check other references for more information.
Using this floating point representation, the problem of memory is solved, but the thing is that operations using floating point numbers are not exact. In order to make an addition the computer needs to shift the decimal point so that the two numbers have the decimal point at the same place. The problem is that every time this is done, information is lost at the other end of the mantissa.
The following example is shown in the book “Validated Numerics” and is due to Rumpf (the creator of Intlab, an interval arithmetic for Matlab). Consider the function

Then, depending on the size of the floating point representation or on the convention made when performing the rounding the evaluation of 





However, when adding those two huge numbers multiple things may happen:
- the computer sees that they are roughly the same so it supposes that their difference is zero
- the computer makes some random operation after the 21th digit in 64 bits (where we roughly have 16 significant digits of precision)
In the end, the result shown is not correct, unless we work with multiple precision arithmetics.
This should not discourage us in using numerical computations, which are useful in many practical application. On the other hand we should be aware that when doing computations in floating point representation results are only approximate. Particular care should be made when subtracting two numbers which are close but which are not exactly represented using the floating point system.
p-Laplace equation – Fixed point approach
The 
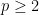

We are not going into details regarding the functional spaces corresponding to 

Using parfor in Matlab
We all know that loops don’t behave well in Matlab. Whenever it is possible to vectorize the code (i.e. use vectors and matrices to do simultaneous operations, instead of one at a time) significant speed-up is possible. However, there are complex tasks which cannot be vectorized and loops cannot be avoided. I recently needed to compute eigenvalues for some 10 million domains. Since the computations are independent, they could be run in parallel. Fortunately Matlab offers a simple way to do this, using parfor.
There are some basic rules one need to respect to use parfor efficiently:
- Don’t use parfor if vectorization is possible. If the task is not vectorizable and computations are independent, then parfor is the way to go.
- Variables used in each computation should not overlap between processors. This is for obvious reasons: if two processors try to change the same variable using different values, the computations will be meaningless in the end.
- You can use an array or cell to store the results given by each processor, with the restriction that processors should work on disjoint parts of the array, so there is no overlap.
The most restrictive requirement is the fact that one cannot use the same variables in the computations for different processors. In order to do this, the simplest way I found was to use a function for the body of the loop. When using a matlab function, all variables are local, so when running the same function in parallel, the variables won’t overlap, since they are local to each function.
So instead of doing something like
parfor i = 1:N commands ... array(i) = result end
you can do the following:
parfor i=1:N array(i) = func(i); end function res = func(i) commands...
This should work very well and no conflict between variables will appear. Make sure to initialize the array before running the parfor, a classical Matlab speedup trick: array = zeros(1,N). Of course, you could have multiple outputs and the output array could be a matrix.
There is another trick to remember if the parpool cannot initialize. It seems that the parallel cluster doesn’t like all the things present in the path sometimes. Before running parfor try the commands
c = parcluster('local');
c.parpool
If you recieve an error, then run
restoredefaultpath
c = parcluster('local');
c.parpool
and add to path just the right folders for your code to work.
Project Euler Problem 285
Another quite nice problem from Project Euler is number 285. The result of the problem depends on the computation of a certain probability, which in turn is related to the computation of a certain area. Below is an illustration of the computation for k equal to 10.

To save you some time, here’s a picture of the case k=1 which I ignored and spent quite a lot of time debugging… Plus, it only affects the last three digits or so after the decimal point…

Here’s a Matlab code which can construct the pictures above and can compute the result for low cases. To solve the problem, you should compute explicitly all these areas.
function problem285(k) N = 100000; a = rand(1,N); b = rand(1,N); ind = find(abs(sqrt((k*a+1).^2+(k*b+1).^2)-k)<0.5); plot(a(ind),b(ind),'.'); axis equal M = k; pl = 1; for k=1:M if mod(k,100)==0 k end r1 = (k+0.5)/k; r2 = (k-0.5)/k; f1 = @(x) (x<=(-1/k+r1)).*(x>=(-1/k-r1)).*(sqrt(r1^2-(x+1/k).^2)-1/k).*(x>=0).*(x<=1); f1 = @(x) f1(x).*(f1(x)>=0); f2 = @(x) (x<=(-1/k+r2)).*(x>=(-1/k-r2)).*(sqrt(r2^2-(x+1/k).^2)-1/k).*(x>=0).*(x<=1); f2 = @(x) f2(x).*(f2(x)>=0); if k == pl thetas = linspace(0,pi/2,200); hold on plot(-1/k+r1*cos(thetas),-1/k+r1*sin(thetas),'r','LineWidth',2); plot(-1/k+r2*cos(thetas),-1/k+r2*sin(thetas),'r','LineWidth',2); plot([0 1 1 0 0],[0 0 1 1 0],'k','LineWidth',3); hold off axis off end A(k) = integral(@(x) f1(x)-f2(x),0,1); end xs = xlim; ys = ylim; w = 0.01; axis([xs(1)-w xs(2)+w ys(1)-w ys(2)+w]); sum((1:k).*A)
Two more mind games solved using Matlab
After doing this, solving the Sudoku puzzle with Matlab, I wondered what else can we do using integer programming? Many of the mind games you can find on the Internet can be modelled as matrix problems with linear constraints. I will present two of them, as well as their solutions, below. The game ideas are taken from www.brainbashers.com. Note that in order to use the pieces of code I wrote you need to install the YALMIP toolbox.
You have a 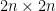




Beni Bogoşel

Click to see my CV
Today’s Visitors

Click for more info
