Archive
Is the Earth flat?
Consider the following experiment: the pairwise distances between four cities on Earth are given. Can you answer the following questions:
1) Can these distances be realized in a flat Earth?
2) Assuming the Earth is spherical and distances are measured along geodesics, can you determine the radius?
The test case was inspired from the following note. The initial test case involves the cities: Seattle, Boston, Los Angeles and Miami. A second test case is provided below.

You can use the Python code to create new test cases of your own.
Read more…Explicit Euler Method – practical aspects
In a previous post I presented the classical Euler methods and how they apply to the simple pendulum equation. Let me now be a little more explicit regarding the coding part. I will present a Python code and give you some main ideas, important from my point of view, regarding the implementation. Here is a summary of these ideas
- Use numpy in Python. When performing numerical simulations related to ODEs it is recommended to work in floating point precision. This will give you accurate enough results (at least for usual academical examples) and will produce a more efficient code.
- Structure the code using functions. The code for the Explicit Euler method should be easily adaptable to other problems, by changing the function defining the ODE (like shown in this post)
- Any numerically implemented method for solving ODEs should be tested on a simple example where the analytical solution is known. In particular, the convergence order of the method can be identified and should coincide with the theoretical prediction. This can easily help debug implementation errors for more complex methods.
- When the ODE comes from an isolated system where there is an invariant (like the energy for the pendulum), the numerical preservation of this invariant should be tested. Errors might be seen, but they should be quantifiable in terms of the step size and the order of the method. Aberrant results here could indicate the presence of a bug.
Simple Pendulum – Euler methods
Given 

In most cases where equation (1) models some real world phenomena, the solutions are not explicit. Therefore, numerical methods are developed in order to solve such problems.
The simple pedulum
 In physics the simple pendulum is a punctual mass fixed at the extremity of a wire without mass and in-extensible (or rigid), which oscillates under the effect of gravity. It is straightforward to see that if the point of attachment of the wire is fixed, then the resulting dynamical system can be uniquely determined knowing the inclination
In physics the simple pendulum is a punctual mass fixed at the extremity of a wire without mass and in-extensible (or rigid), which oscillates under the effect of gravity. It is straightforward to see that if the point of attachment of the wire is fixed, then the resulting dynamical system can be uniquely determined knowing the inclination 



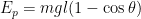

Supposing the system is isolated and no energy is lost due to friction we have that the derivative of the energy 

Checking the gradient and Hessian implementation using finite differences
Solving a numerical optimization problem depends not only on the optimization algorithm you use, but also on the fact that you implemented correctly the gradient and, eventually, the Hessian matrix associated to the function you want to optimize. The correct implementation of the partial derivatives is not always a trivial calculus question, where you have an analytic formula for your function and you just need to take care when performing the computations. However, even the best students can make a typing error, put a wrong sign somewhere, miss a factor, etc, and in that case the optimization algorithm simply doesn’t work as expected.
Things get even more complicated when the computation of the gradient (and Hessian) goes through some PDE model, multiplying the places in your code where an error might hide. For example in some parametric shape optimization problem, one has a parametric description of the shape and the gradient of the function to be optimized is obtained by putting in the associated shape derivative formula a perturbation field associated to the variation in the corresponding parameter.
Read more…Gradient algorithm with optimal step: Quadratic Case: theory
In a previous post I looked at the theory behind the convergence of the gradient descent algorithm with fixed step for a quadratic function. In this post I will treat a similar topic, namely the gradient descent algorithm with optimal step for the case of a quadratic function. Let us consider again 

the classical quadratic function, where 


where the descent step 

is minimal.
Read more…Gradient algorithm: Quadratic Case: theory
Everyone who did a little bit of numerical optimization knows the principle gradient descent algorithm. This is the simplest gradient based algorithm: given the current iterate, advance in the opposite direction of the gradient with a given step

It is straightforward to see that if 



This means that there exists a 

Recurrences converging to the wrong limit in finite precision
Consider the following recurrence:

a) Study this recurrence theoretically: prove that the sequence converges and find its limit.
b) Implement the recurrence using the programming language of your choice and see what is the limit obtained by numerical investigation. Interpret the results!
Read more…Gradient Descent converging to a Saddle Point
Gradient descent (GD) algorithms search numerically for minimizers of functions 


where 
However, the “almost always” part from the above sentence is in itself interesting. It turns out that the choice of the initialization may lead the algorithm to get stuck in a Saddle Point, i.e. a critical point where the Hessian matrix has both positive and negative eigenvalues. The way to imagine such examples is to note that at such a Saddle Point there are directions for which
To better illustrate this phenomenon, let’s look at a two dimensional example:

It can be seen immediately that this function has critical points at 


Note that looking only along the line 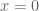




One simple way to prevent GD algorithms being stuck in a saddle point is to consider randomized initializations so that you avoid any bias you might have regarding the objective function.
On Heron’s algorithm – approximating the square root
Heron’s algorithm computes an approximation of the square root of a positive real number using the iteration

- Show that the recurrence defined above is Newton’s algorithm applied for finding a zero of the function
. Show that the sequence
converges to
when
is close enough to
This choice simplifies the computations and is an estimation of half the relative error when
.
- Show that the sequence
Deduce an explicit formula for
in terms of
. Show that the sequence
converges to
.
- Show that for every
there exists an integer
such that
. Write a modified Heron algorithm which reduces the computation of the square root of
.The choice of the initialization
and we look at the choice of the initial condition. We will suppose that the initial condition depends on
, a constant function and
, a polynomial of degree
in
. In every case we will try to minimize
for
.
- Show that if
then
is minimal for
. Find the explicit value of
. (Hint: You could represent graphically the function
.)
- Suppose that
and
with
.
(a) Prove that the maximum ofis found for
.
(b) Show that in order to minimizeit is necessary that
and that
.
(c) Conclude that the. Find an exact expression for
- For
compare the number of iterations necessary to arrive at a demanded precision (
for the two initializations studied:
and
with
- Evaluate the number of operations used for the two cases and conclude which of the two approaches is more advantageous.
- Try to find the initialization of second degree which is optimal and perform a similar investigation to see if from the point of view of the number of operations this choice is well adapted or not.


Condition number of a matrix
Let 


The condition number of a matrix gives an idea on the behavior of the solutions 



1. If 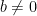

where

This quantity is the condition number of
2. Show that if

where 

3. Consider the following example (attributed to H. Rutishauser) :

Compute the determinant of 

- compute the eigenvalues of
- use “numpy.linalg.cond”
Conclude that the lower bound found previously was not so far from the condition number. Try to find other examples of 

Integrating an oscillatory function
Consider the function ![{f: [0,1] \rightarrow [-1,1], \ f(x) = \sin(1/x)}](https://s0.wp.com/latex.php?latex=%7Bf%3A+%5B0%2C1%5D+%5Crightarrow+%5B-1%2C1%5D%2C+%5C+f%28x%29+%3D+%5Csin%281%2Fx%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)




1. Use your favorite numerical tool (for example \texttt{scipy.integrate}) in order to evaluate directly the integral 
![{[0,1]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
2. Consider the decreasing sequence 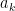
![{[a_{k+1},a_k]}](https://s0.wp.com/latex.php?latex=%7B%5Ba_%7Bk%2B1%7D%2Ca_k%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
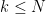

3. Show that

Evaluate this expression with the aid of a numerical software and compare the precision to the result obtained at the previous points. Explain the eventual gain of precision compared to point 1. 4. The function integral cosine is defined by

Prove that 
Remark: The precise evaluation of 



where 


Show that the integral 
![{\gamma_0 : [0,1]\rightarrow \Bbb{C}}](https://s0.wp.com/latex.php?latex=%7B%5Cgamma_0+%3A+%5B0%2C1%5D%5Crightarrow+%5CBbb%7BC%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![{\gamma_1 : [0,1] \rightarrow \Bbb{C}}](https://s0.wp.com/latex.php?latex=%7B%5Cgamma_1+%3A+%5B0%2C1%5D+%5Crightarrow+%5CBbb%7BC%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

Prove that 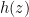
![{\arg z \in [0,\pi]}](https://s0.wp.com/latex.php?latex=%7B%5Carg+z+%5Cin+%5B0%2C%5Cpi%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

Prove that on the new path the function 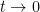
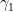

Use a numerical tool (e.g. \texttt{scipy.integrate}) to compute the integral of

Compare the result to the ones obtained before and conclude why the numerical software manages to approximate correctly the integral of
What can go wrong with numerics
I recently watched the video Validated Numerics by Warwick Tucker. This video is an introduction to interval arithmetic, which is a rigorous way of doing numerics with nice applications. In the first part of the video, however, he starts by showing some examples where the numerics can go wrong.
First, in order to understand why computations done by a machine can be wrong, you need to know how the computer looks at numbers. Since the computer has a finite amount of memory, it will never store exact representations. Irrational numbers with infinitely many digits repeating without any pattern whatsoever are clearly not representable. Even rational numbers, which are the ratios of two integers may be costly to represent if the integers involved are quite large. When working with simulations one often manipulates not one variable but vectors and matrices with millions of variables. Therefore it is necessary to bound the memory allocated to each one of these variables. This is why the floating point arithmetic was introduced.
A floating point number (in some basis, binary for the computer, decimal for the usual representation) is composed of a real number m called the mantissa and an exponent e. The catch is that the mantissa will store only finitely many digits and usually it is normalized, i.e. there are no zeros after the decimal point. For example:
- 1.01011 is a valid mantissa with 5 binary digits (the leading 1 is not counted)
- 0.00101 is not a normalized mantissa since there are zeros after the decimal point
- 1011.01 is not a normalized mantissa since there are more then one digits before the decimal point
The mantissa alone, in binary representation, will only represent numbers between 1 and 2. However, one can reach more numbers using a multiplication with a power of two, contained in the exponent. Therefore, the computer knows a number by its finite precision mantissa and its exponent. The sign of the number can also be included in one bit. I will not try to make an exhaustive lecture on floating point representations: you should check other references for more information.
Using this floating point representation, the problem of memory is solved, but the thing is that operations using floating point numbers are not exact. In order to make an addition the computer needs to shift the decimal point so that the two numbers have the decimal point at the same place. The problem is that every time this is done, information is lost at the other end of the mantissa.
The following example is shown in the book “Validated Numerics” and is due to Rumpf (the creator of Intlab, an interval arithmetic for Matlab). Consider the function

Then, depending on the size of the floating point representation or on the convention made when performing the rounding the evaluation of 





However, when adding those two huge numbers multiple things may happen:
- the computer sees that they are roughly the same so it supposes that their difference is zero
- the computer makes some random operation after the 21th digit in 64 bits (where we roughly have 16 significant digits of precision)
In the end, the result shown is not correct, unless we work with multiple precision arithmetics.
This should not discourage us in using numerical computations, which are useful in many practical application. On the other hand we should be aware that when doing computations in floating point representation results are only approximate. Particular care should be made when subtracting two numbers which are close but which are not exactly represented using the floating point system.
FreeFem++ Tutorial – Part 1
First of all, FreeFem is a numerical computing software which allows a fast and automatized treatment of a variety of problems related to partial differential equations. Its name, FreeFem, speaks for itself: it is free and it uses the finite element method. Here are a few reasons for which you may choose to use FreeFem for a certain task:
- It allows the user to easily define 2D (and 3D) geometries and it does all the work regarding the construction of meshes on these domains.
- The problems you want to solve can be easily written in the program once we know their weak forms.
- Once we have variables defined on meshes or solutions to some PDE, we can easily compute all sorts of quantities like integral energies, etc.
Before showing a first example, you need to install FreeFem. If you are not familiar with command line work or you just want to get to work, like me, you can install the visual version of FreeFem which is available here. Of course, you can find example programs in the FreeFem manual or by making a brief search on the internet.
I’ll present some basic stuff, which will allow us in the end to solve the Laplace equation in a circular domain. Once we have the structure of the program, it is possible to change the shape of the domain in no time.
Even small errors can be fatal
Machines and computers represent numbers as sequences of zeros and ones called bits. The reason for doing this is the simplicity of constructing circuits dealing with two states. This fact coupled with limited memory capacities means that from the start we cannot represent all numbers in machine code. It is true that we can get as close as we want to any number with great memory cost when precision is important, but in fact we always use a fixed precision. In applications this precision is fixed to a number of bits (16, 32, 64) which correspond to significant digits in computations. Doing math operations to numbers represented on bits may lead to loss of information. Consider the following addition using 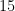

notice that using only the first 
Solving Poisson’s equation on a general shape using finite differences
One of the questions I received in the comments to my old post on solving Laplace equation (in fact this is Poisson’s equation) using finite differences was how to apply this procedure on arbitrary domains. It is not possible to use this method directly on general domains. The main problem is the fact that, unlike in the case of a square of rectangular domain, when we have a general shape, the boudary can have any orientation, not only the orientation of the coordinate axes. One way to avoid approach this problem would be using the Finite Element Method. Briefly, you discretize the boundary, you consider a triangulation of the domain with respect to this discretization, then you consider functions which are polynomial and have support in a few number of triangles. Thus the problem is reduced to a finite dimensional one, which can be written as a matrix problem. The implementation is not straightforward, since you need to conceive algorithms for doing the discretization and triangulation of your domain.
One other approach is to consider a rectangle 



Note that doing this we do not need to impose the boundary condition 


Simple optimization problem regarding distances
Given 


For 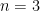
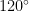
For 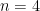

In general, we cannot precisely say what is the position of the solution. Providing a numerical algorithm which computes the optimal position of
Numerical method – minimizing eigenvalues on polygons
I will present here an algorithm to find numerically the polygon 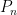

The first question is: how do we calculate the eigenvalues of a polygon? I adapted a variant of the method of fundamental solutions (see the general 2D case here) for the polygonal case. The method of fundamental solutions consists in finding a function which already satisfies the equation 



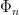

in order to find the desired eigenfunction. Since we cannot solve numerically this system for every 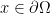


and this system has a nontrivial solution if and only if the matrix 


Best approximation of a certain square root
Let 

holds for an infinity of pairs 

Distance from a point to an ellipsoid
Here I will discuss the problem of finding the point which realizes the minimal distance from a given
This problem is interesting in itself, but has some other applications. Sometimes in optimization problems we need to impose a quadratic constraint, so after a gradient descent we always project the result on the constraint which is an ellipsoid.
Let’s begin with the problem, which can be formulated in a general way like this: we are given 


(note that the square is not important here, but simplifies the computations later)
Beni Bogoşel

Click to see my CV
Today’s Visitors

Click for more info
