Archive
Iterative algorithms – Convergence rates
In optimization and any other iterative numerical algorithms, we are interested in having convergence estimates for all algorithms. We are not only interested in showing that the error goes to 
Generally, there are two points of view for convergence: convergence in terms of 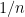


To fix the ideas, denote 
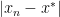
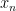

We have the following standard classification:
- linear convergence: there exists
such that
the constant
, so in particular
.
- sublinear convergence:
- superlinear convergence:
with any positive convergence ratio
- {convergence of order
}: there exists
such that for
large enough
is called the order of convergence
has a special name: quadratic convergence

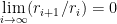
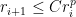
To underline the significant difference between linear and superlinear convergence consider the following examples: Let 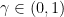
converges linearly to zero, but not superlinearly
converges superlinearly to zero, but not quadratically
converges to zero quadratically
Quadratic convergence is much faster than linear convergence.
Among optimization algorithm, the simpler ones are usually linearly convergent (bracketing algorithms: trisection, Golden search, Bisection algorithm, gradient descent). Algorithms involving higher order information or approximation are generally superlinear (Secant method, Newton, BFGS or LBFGS in higher dimensions etc.).
There is a huge difference between linear convergence and super-linear convergence. If a faster algorithm is available using it is surely useful!
Golden search algorithm – efficient 1D gradient free optimization
Bracketing algorithms for minimizing one dimensional unimodal functions have the form:
- Suppose
is an interval containing the minimizer
- Pick
in
- If
then choose
- If
then choose
- Stop the process when
![{[a_{n+1},b_{n+1}] = [a_n,x^+]}](https://s0.wp.com/latex.php?latex=%7B%5Ba_%7Bn%2B1%7D%2Cb_%7Bn%2B1%7D%5D+%3D+%5Ba_n%2Cx%5E%2B%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[a_{n+1},b_{n+1}] = [x^-,b_n]}](https://s0.wp.com/latex.php?latex=%7B%5Ba_%7Bn%2B1%7D%2Cb_%7Bn%2B1%7D%5D+%3D+%5Bx%5E-%2Cb_n%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
The simplest algorithm corresponds to choosing 

Optimizing a 1D function – trisection algorithm
Optimization problems take the classical form
Not all such problems have explicit solution, therefore numerical algorithms may help approximate potential solutions.
Numerical algorithms generally produce a sequence which approximates the minimizer. Information regarding function values and its derivatives are used to generate such an approximation.
The easiest context is one dimensional optimization. The basic intuition regarding optimization algorithms starts by understanding the 1D case. Not all problems are easy to handle for a numerical optimization algorithm. Take a look at the picture below:

Maximize the circumradius of a unit diameter simplex
Given a simplex in dimension 


Consider 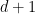
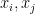
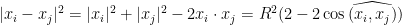
An immediate upper bound, which is tight can be obtained from the identity 

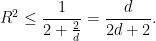
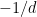
Minimal volume of some particular convex sets in the cube
Consider a cube and a convex body 
Graham’s Biggest Little Hexagon
Think of the following problem: What is the largest area of a Hexagon with diameter equal to 1?
As is the case with many questions similar to the one above, called polygonal isoperimetric problems, the first guess is the regular hexagon. For example, the largest area of a Hexagon with fixed perimeter is obtained for the regular hexagon. However, for the initial question, the regular hexagon is not the best one. Graham proved in his paper “The largest small hexagon” that there exists a better competitor and he showed precisely which hexagon is optimal. More details on the history of the problem and more references can be found in Graham’s paper, the Wikipedia page or the Mathworld page.
I recently wanted to use this hexagon in some computations and I was surprised I could not find explicitly the coordinates of such a hexagon. The paper “Isodiametric Problems for Polygons” by Mossinghoff was as close as possible to what I was looking for, although the construction is not explicit. Therefore, below I present a strategy to find what is the optimal hexagon and I will give a precise (although approximate) variant for the coordinates of Graham’s hexagon.
Read more…Checking the gradient and Hessian implementation using finite differences
Solving a numerical optimization problem depends not only on the optimization algorithm you use, but also on the fact that you implemented correctly the gradient and, eventually, the Hessian matrix associated to the function you want to optimize. The correct implementation of the partial derivatives is not always a trivial calculus question, where you have an analytic formula for your function and you just need to take care when performing the computations. However, even the best students can make a typing error, put a wrong sign somewhere, miss a factor, etc, and in that case the optimization algorithm simply doesn’t work as expected.
Things get even more complicated when the computation of the gradient (and Hessian) goes through some PDE model, multiplying the places in your code where an error might hide. For example in some parametric shape optimization problem, one has a parametric description of the shape and the gradient of the function to be optimized is obtained by putting in the associated shape derivative formula a perturbation field associated to the variation in the corresponding parameter.
Read more…Gradient algorithm with optimal step: Quadratic Case: theory
In a previous post I looked at the theory behind the convergence of the gradient descent algorithm with fixed step for a quadratic function. In this post I will treat a similar topic, namely the gradient descent algorithm with optimal step for the case of a quadratic function. Let us consider again 

the classical quadratic function, where 


where the descent step 

is minimal.
Read more…Gradient algorithm: Quadratic Case: theory
Everyone who did a little bit of numerical optimization knows the principle gradient descent algorithm. This is the simplest gradient based algorithm: given the current iterate, advance in the opposite direction of the gradient with a given step

It is straightforward to see that if 


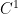

This means that there exists a 

Are zero-order optimization methods any good?
The short answer is yes, but only when the derivative of gradient of the objective function is not available. To fix the ideas we refer to:
- optimization algorithm: as an iterative process of searching for approximations of a (local/global) minimum of a certain function
- zero-order algorithm: an optimization method which only uses function evaluations in order to decide on the next point in the iterative process.

Therefore, in view of the definitions above, zero-order algorithms want to approximate minimizers of a function using only function evaluations; no further information on derivatives is available. Classical examples are bracketing algorithms and genetic algorithms. The objective here is not to go into detail in any of these algortihms, but to underline one basic limitation which must be taken into account whenever considering these methods.
In a zero-order optimization algorithm any decision regarding the choice of the next iterate can be made only by comparing the values of 
![{[a,b]}](https://s0.wp.com/latex.php?latex=%7B%5Ba%2Cb%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[a,x^*]}](https://s0.wp.com/latex.php?latex=%7B%5Ba%2Cx%5E%2A%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[x^*,b]}](https://s0.wp.com/latex.php?latex=%7B%5Bx%5E%2A%2Cb%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
- given the bracketing
choose the points
and
.
- compare the values
and
in order to decide on the next bracketing interval:if
then
if
then
- stop when the difference
is small enough.
![{[a_{i+1},b_{i+1}]=[a_i,x_+]}](https://s0.wp.com/latex.php?latex=%7B%5Ba_%7Bi%2B1%7D%2Cb_%7Bi%2B1%7D%5D%3D%5Ba_i%2Cx_%2B%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[a_{i+1},b_{i+1}]=[x_-,b_i]}](https://s0.wp.com/latex.php?latex=%7B%5Ba_%7Bi%2B1%7D%2Cb_%7Bi%2B1%7D%5D%3D%5Bx_-%2Cb_i%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
One question immediately rises: can such an algorithm reach any desired precision, for example, can it reach the machine precision, i.e. the precision to which computations are done in the software used? To fix the ideas, we’ll suppose that we are in the familiar world of numbers written in double precision, where the machine precision is something like 
More precisely, the real numbers are stored as floating point numbers and only 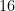

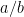



This issue related to computations done in floating point precision makes the question of comparing 



where 
Coming back to our previous paragraph, it turns out that the computer won’t be able to tell the difference between 


where

the machine won’t tell the difference between 
Therefore, when using a zero-order algorithms for a function 
When using derivatives or gradients there is no such problem, since we can decide if we are close enough to 
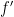
In conclusion, use zero-order methods only if gradient based methods are out of reach. Zero-order methods are not-only slowly convergent, but may also be unable to achieve the expected precision in the end.
Optimality conditions – equality constraints
Everyone knows that local minima and maxima of a function 
The situation changes when dealing with constraints. Consider a simple example, like 
Since a picture is worth 1000 words, let me share with you two pictures 🙂 Consider the minimization of 

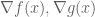


It becomes obvious that if the two gradients are not aligned, then there exists a component of 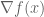
Of course, this geometric argument is not the whole picture, but it gives an important insight, which directly implies the theory of Lagrange multipliers: at the optimum, the gradient 

Now, once we understood the intuition behind this, it remains to see under which conditions there exists a tangent space to the constraints set, and see rigorously why the above relation holds. But all this is left for some future post.
Gradient Descent converging to a Saddle Point
Gradient descent (GD) algorithms search numerically for minimizers of functions 


where 
However, the “almost always” part from the above sentence is in itself interesting. It turns out that the choice of the initialization may lead the algorithm to get stuck in a Saddle Point, i.e. a critical point where the Hessian matrix has both positive and negative eigenvalues. The way to imagine such examples is to note that at such a Saddle Point there are directions for which
To better illustrate this phenomenon, let’s look at a two dimensional example:

It can be seen immediately that this function has critical points at 


Note that looking only along the line 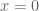




One simple way to prevent GD algorithms being stuck in a saddle point is to consider randomized initializations so that you avoid any bias you might have regarding the objective function.
Computing the Shape Derivative of the Wentzell Problem
Computing shape derivatives is a nice thing to know if you do numerical shape optimization. When you want to minimize a quantity depending on a shape in a more or less direct way, you should be able to differentiate it so that gradient algorithms could be applied. Computing shape derivatives is not that easy, but below there is a method which is not that hard once you practice some simple examples. For some bibliography on the subject I present you the following:
- Jean CEA, Conception optimale ou identification de formes, calcul rapide de la dérivée directionnelle de la fonction coût: this is in French, but it presents the method nicely.
- Chicco-Ruiz, Morin, Pauletti, The shape derivative of the Gauss curvature. This is not an original source of the classical results, but it contains a very nice summary of the basic notions of shape derivatives.
- Delfour, Zolesio, Shapes and Geometries
- Henrot, Pierre, Shape Variation and Optimization
- Gregoire Allaire, see his the shape optimization course on his homepage
We start directly with a complicated example, containing some complex boundary terms. The Wentzell eigenvalue problem is given by the following:

It is not hard to see that the associated variational formulation is given by

Lagrangians – derivation under constraints
In this post I will describe a formal technique which can help in finding derivatives of functions under certain constraints. In order to see what I mean, take the following two examples:
1. If you differentiate the function 

2. If you differentiate the function 
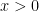


This shows that adding certain constraints will change the derivative and when dealing with more sophisticated constraints, like PDE or differential equations, things get less clear.
The question of the existence of derivatives with respect to some variables, when dealing with constraints, is usually dealt with by using the implicit function theorem: this basically says that if some variables are linked by some smooth equations and that you can locally invert the dependence, then you can infer differentiability.
The method presented below skips this step and goes directly for the computation of the derivative. This is a common used technique in control theory or shape optimization, where computing derivatives is essential in numerical simulations. I will come back to derivatives linked to shape optimization in some further posts. For now, let’s see how one can use the Lagrangian method for computing derivatives in some simple cases.
Example 1. Let’s compute the derivative of 

Example of optimization under constraints – using Lagrange multipliers
Consider the functional 

and the set 

- Prove that
- Let
be the set
. Does
Proof: This is a problem which illustrates well concepts related to optimality conditions for constrained problems. It is possible to solve these problems by two methods: one using only basic ideas and a second one using results from optimization theory. One can also see by examining the basic method how to recover naturally the optimality condition given by the Lagrange multipliers.
Optimizing a quadratic functional under affine constraints
Consider the quadratic functional 

for a 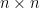




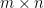

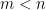

where 
- Show that
- Prove that if
is the minimizer of
such that
solves the linear system
- Show that the matrix of the above system is invertible.

Project Euler 607
If you like solving Project Euler problems you should try Problem number 607. It’s not very hard, as it can be reduced to a small optimization problem. The idea is to find a path which minimizes time, knowing that certain regions correspond to different speeds. A precise statement of the result can be found on the official page. Here’s an image of the path which realizes the shortest time:

Project Euler tips
A few years back I started working on Project Euler problems mainly because it was fun from a mathematical point of view, but also to improve my programming skills. After solving about 120 problems I seem to have hit a wall, because the numbers involved in some of the problems were just too big for my simple brute-force algorithms.
Recently, I decided to try and see if I can do some more of these problems. I cannot say that I’ve acquired some new techniques between 2012-2016 concerning the mathematics involved in these problems. My research topics are usually quite different and my day to day programming routines are more about constructing new stuff which works fast enough than optimizing actual code. Nevertheless, I have some experience coding in Matlab, and I realized that nested loops are to be avoided. Vectorizing the code can speed up things 100 fold.
So the point of Project Euler tasks is making things go well for large numbers. Normally all problems are tested and should run within a minute on a regular machine. This brings us to choosing the right algorithms, the right simplifications and finding the complexity of the algorithms involved.
IMC 2016 – Day 2 – Problem 7
Problem 7. Today, Ivan the Confessor prefers continuous functions ![{f:[0,1]\rightarrow \Bbb{R}}](https://s0.wp.com/latex.php?latex=%7Bf%3A%5B0%2C1%5D%5Crightarrow+%5CBbb%7BR%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![{x,y \in [0,1]}](https://s0.wp.com/latex.php?latex=%7Bx%2Cy+%5Cin+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

SIAM 100 digit challenge no 4 – Matlab solution
In 2002 the SIAM News magazine published a list of 

Problem 4. What is the global minimum of the function

Beni Bogoşel

Click to see my CV
Today’s Visitors

Click for more info
